Big Model Fine-tuning Practical Guide: 3 Key Steps to Make You Take 80% Less Curves
In today’s furious advancement of AI technology, 83% of the world’s enterprises have applied big language models to actual business scenarios. But shockingly, more than half are still repeating a fatal mistake – using unfine-tuned general-purpose big models for specialized domain tasks. This "trimming down" practice is costing organizations billions of dollars a year in computing resources and business opportunities.
Data scientist Li Ming (a pseudonym) had a representative experience: his medical technology company spent millions of dollars on computing resources, but was repeatedly frustrated in pathology analysis scenarios. The model without fine-tuning is like a Michelin chef with a kitchen knife, but it frequently fails in areas that require scalpel-level precision. This case reveals a cruel fact: enterprises that do not fine-tune large models are swimming naked in the age of artificial intelligence.

I. The life-and-death game of framework selection: why do 90% of projects fall at this step?
In the starry sea of the open source community, LLaMA-Factory with absolute advantage to occupy the minds of developers. This supports 30+ mainstream models at home and abroad "Universal Factory", not only compatible with the whole process from pre-training to reinforcement learning, but also provides CLI, WebUI, Python three kinds of interaction. Compared with other frameworks, its advantages are:
- Support for domestic big model ecology (Baichuan, ChatGLM3, Qwen2, etc.) Parameter efficiency optimization technology (QLoRA) reduces graphics memory consumption by 70%
- Visualized training monitoring system captures model dynamics in real time
But what really shook up the industry was Amazon CloudTech’s open source ModelHub solution. This SageMaker-based platform lowers the fine-tuning threshold to "drag-and-drop operations":
.
- Support zero code to complete 10 billion parameter model training
- Automatically matches the optimal hardware configuration (e.g. P4d example with NVIDIA A100)
- Built-in cost optimization algorithms save 40% of training expenses
.
.
.
Big language model fine-tuning: a practical guide to making AI more understanding
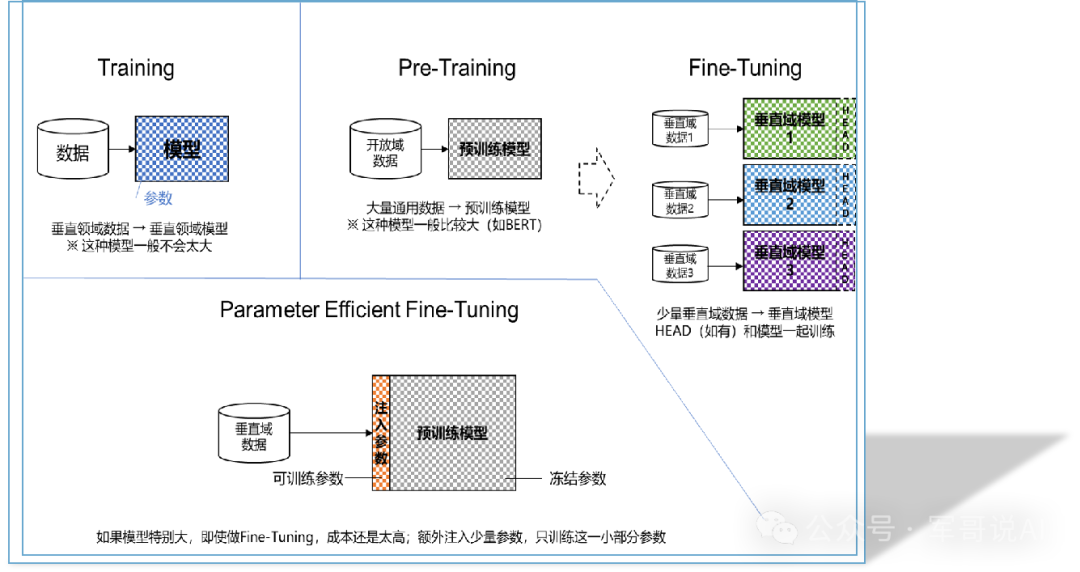
When a generalized large model cannot meet specific business needs, "model fine-tuning" becomes the key to break the game. How to train the most adapted intelligent brain with the least resources? In this article, we will unveil the practical code of fine-tuning large language models for you.
I. The three core methods of model fine-tuning- Full-parameter fine-tuning
Principle: Adjust all the parameters of the model to fully adapt to the new task
Advantage: extremely high performance ceiling, suitable for large data-volume scenarios
Limitations: like the overall reinforcement of the skyscraper, need to consume a large amount of computing power (the cost of a single training can be up to several hundreds of thousands of dollars) - LoRA technology
Innovation point: only training low-rank fitness matrix, parameter update less than 1% of the original model
Advantage: the king of cost-effective, 8GB of video memory can be fine-tuned to the 7 billion parameter model
Measurement data: compared to the full-parameter fine-tuning, the performance gap of no more than 5%, the training speed increased by 3 times
.
3. PEFT Series Methods
Representative Technologies: Prefix Tuning, Adapter Tuning
Features: insert "memory modules" in specific locations of the model
Applicable Scenarios: customer service speech adaptation, terminology optimization and other lightweight requirementsII, the golden formula for the choice of power
.
Correspondence table between model parameters and memory requirements:
7B model: 24GB memory required (1 A10 card)
13B model: 40GB memory required (2 A10 clusters)
70B model: 320GB memory required (8 card clusters)
Selection strategy:
- Startup team: choose Llama-7B+LoRA solution
- Medium-sized organizations: Baichuan-13B + full-parameter fine-tuning
- Head organizations: Qwen-72B + hybrid training program
III, LLaMA-Factory practical four-step method
Correspondence table between model parameters and memory requirements:
Model parameters and memory requirements:
Model parameters and memory requirements:
Model parameters and memory requirements:

- Data Preprocessing
Obeying the "quality>quantity" principle, the cleaned data needs to fulfill:
- 200-500 tokens/bar
- Complete mapping with instruction-input
- Reject duplicate/conflicting samples
- Example profile settings:
learning_rate = 3e-5 batch_size = 32 num_epochs = 5 lora_rank = 8 - Terminal start command:
```
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path path_to_model \
--dataset your_data \
--lora_rank 8
4. Training monitoring points:
- Loss values need to decrease steadily (fluctuations <0.1 recommended)
- Save checkpoints every 100 steps
- Keep an eye on the memory utilization rate (<80% recommended).
## 4. Five rules of thumb for parameter tuning
The five rules of parameter tuning are. [Data Preprocessing, Model Fine-tuning, Parameter Tuning](http://res.cloudinary.com/dnw6ccjxg/image/upload/v1744863625/95700b96d797a4dbbcda1e501b3e1670_jipgny.png)
1. Learning rate setting:
- Full parameter fine-tuning: 20% of the reference base learning rate
- LoRA fine-tuning: recommended 3e-5 to 1e-4 interval
2. batch size metaphysics:
Memory utilization = (batch size x sequence length)/memory capacity
The optimal value is usually in the range of 0.7-0.8
3. Early stop mechanism:
3 consecutive epoch validation set indicators do not improve the termination of training
4. Mixed precision training:
Enable fp16 mode to save 30% memory, but be aware of the risk of gradient overflow.
5. golden checkpoint:
Choose the intermediate model with the highest accuracy in the validation set instead of the final model.
## V. Three typical cases of industry landing
**Case 1: Financial customer service optimization**
- Use Qwen-7B for instruction fine-tuning
- Injected 2,000 compliant conversations
- Conversation violation rate decreased by 82%.
**Case 2: Medical Knowledge Base Building
- Using ChatGLM3-6B + LoRA
- Trained 20,000 consultation records
- Diagnostic recommendation accuracy rate increased to 91
**Case 3: Intelligent Customer Service for Cross-border E-commerce
- Based on Baichuan-13B multilingual model.
- Fusion of English/French/Spanish trilingual data
- Increase response speed by 4 times and reduce labor cost by 60%.
When the technical fog gradually clears, we will find that the essence of model fine-tuning is the process of letting general-purpose intelligences obtain exclusive memories. In this era of ever-changing AI technology, mastering fine-tuning technology is like getting a golden key to open the treasure trove of exclusive intelligence. However, it should be remembered that excellent data quality + accurate parameter adjustment = successful fine-tuning, which is always more important than simply pursuing the model size.