Big model alchemy: demystifying the three core technologies of ai evolution
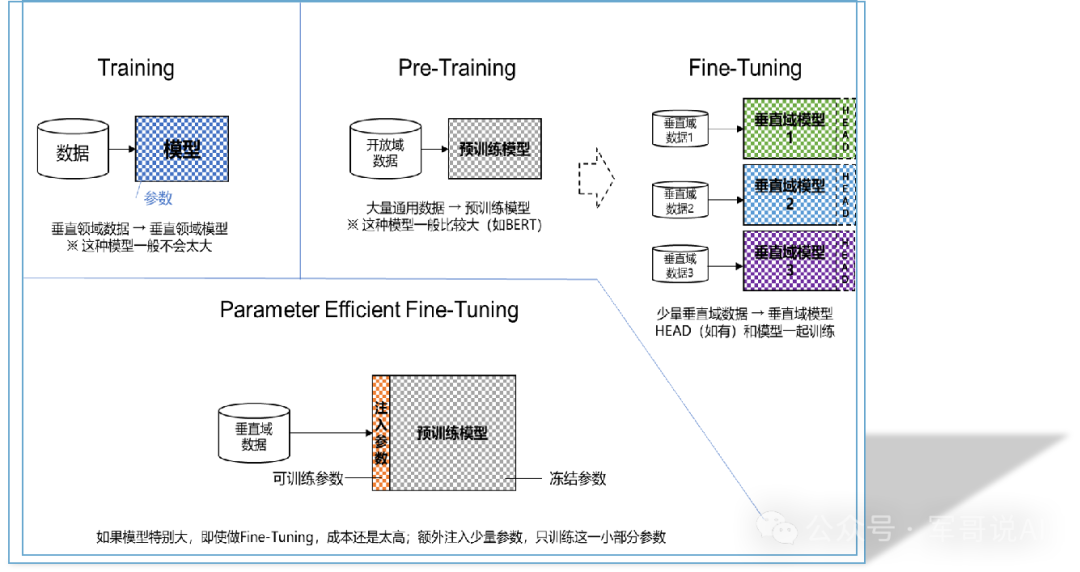
Fine-tuning: let AI know your mind better
When ChatGPT can write works comparable to poets, and when Midjourney can generate stunning art paintings, behind these seemingly magical AI capabilities lies a key process – fine-tuning. This technology is like putting a professional filter on the AI, allowing the general-purpose model to morph into a domain expert.

In Google Labs, engineers were able to transform basic big models into specialized physician assistants with just hundreds of medical Q&A samples. This is thanks to the unique "four-two-thousand-pound" feature of fine-tuning technology: instead of re-training trillions of parameters, simply adjusting key neurons allows the model to accurately master new skills. This "surgical" optimization preserves the model’s original knowledge base and gives it a fiery eye in its area of expertise.
But fine-tuning is not a panacea. The emergence of Parameter Efficient Fine-Tuning (PEFT) technology has reduced computational resource consumption by 90%, enabling ordinary startup teams to train proprietary AI models. It’s like putting wings on an elephant to maintain large volume while enabling flexible steering.
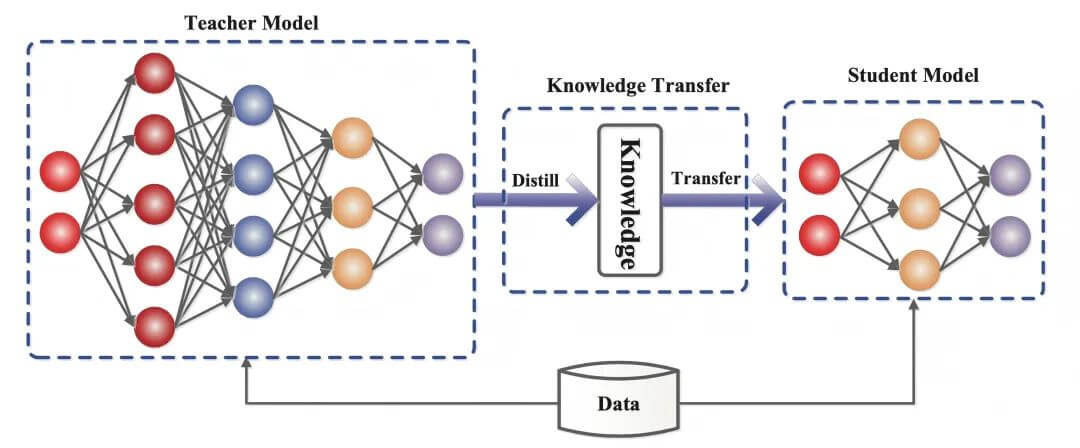
Distillation: the wisdom of packing light
While tech giants are obsessed with building models with hundreds of billions of parameters, distillation technology is kicking off another silent revolution. The technique is like condensing an encyclopedia into a pocketbook, compressing the model volume to one-tenth of its original size while retaining core knowledge.
The Google search team used a large model to pre-generate a vocabulary of vaccine-related terms, and then injected it into a lightweight model through distillation technology, realizing real-time searches in 50 languages. This "teacher-student inheritance" model allows the compact "student model" to inherit the wisdom of the "teacher model" but also run smoothly on the phone. It’s like taking a Michelin chef’s cooking secrets and condensing them into a home-cooked recipe.
But distillation is not simply compression. By conveying probability distributions rather than hard labels, student models can perceive knowledge boundaries, and in scenarios such as medical diagnosis, this "fuzzy correctness" is more realistically valuable than "precise error". This is the subtlety of distillation technology – expressing richer semantics with fewer parameters.
Hint engineering: the art of talking to AI
At a San Francisco startup, engineers automate the generation of compliant legal documents from generic models using carefully designed prompt templates. This demonstrates the magic of prompt engineering: the potential of AI can be unlocked without modifying model parameters, just by typing in the design.
Single-sample prompts are like showing the AI a standard answer, while fewer-sample prompts are like a miniature training class. When a user inputs "apple:", zero-sample prompts may get introduced by the tech company, and after adding the example of "peach:drupe", the model will be able to accurately output "apple:rosaceae". This contextual learning capability gives AI the elasticity to truly think in terms of examples.
Recent research shows that proper cue design can improve model performance by 40%. In New Crown Vaccine Information Processing, engineers enabled the AI to automatically recognize more than 800 variants of vaccine-related expressions through a combination of multi-layered cues. This "language magic" is reshaping the new paradigm of human-machine collaboration.
Boundaries and Responsibilities of Intelligent Evolution
While we marvel at these technological marvels, Stanford’s Ethics Lab is sounding the alarm: models may inherit biases from training data, and medical diagnostic models may amplify racial disparities. This requires practitioners to be both technologically savvy and deeply ethical.

The Google Developer Code specifically emphasizes the need to follow the guidelines of the Data Module and the Fairness Module. Just as medieval alchemists sought to "turn stone into gold", modern AI engineers are looking for a balance between performance and ethics. The application of offline reasoning technology ensures processing efficiency while leaving a window period for manual review.
From fine-tuning to distillation, from cue engineering to offline reasoning, these technologies are weaving the warp and woof of the intelligent age. As we stand on the shoulders of the arithmetic giants and look into the future, we need to bear in mind more than ever: the true evolution of intelligence is always a double helix of instrumental rationality and humanistic care. ## Introduction
In today’s wildly advancing AI, large-scale language models are like the alchemists of the digital world, capable of creating amazing value with just a few simple hints. But for these "generalists" to truly become industry experts, fine-tuning techniques are becoming a golden rod in the hands of developers. As we stand at the crossroads of arithmetic and data, six disruptive fine-tuning methods are rewriting the rulebook for AI training.
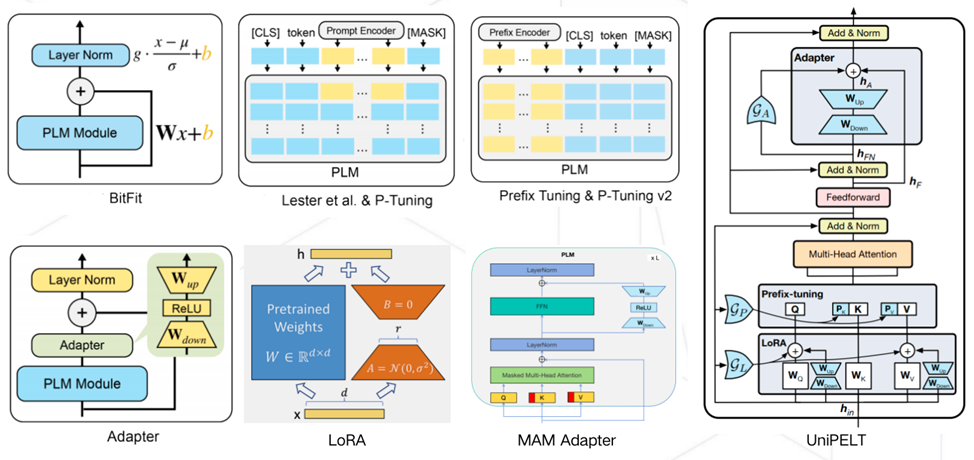
I. Freeze methods: the preferred solution for lightweight fine-tuning
Freezing most of the model parameters and unfreezing only the key network layers of the training strategy is like doing precise "brain surgery" on an AI model. This approach focuses resources on optimizing specific task modules by locking down the model’s underlying cognitive system, allowing the fine-tuning of tens of billions of parameter models to be accomplished with only a consumer-grade graphics card. In verticals such as medical report generation and legal document parsing, the Freeze method is creating the industry miracle of "doing big things at a small cost".
II. p-tuning: let the model listen to "strings outside the voice"
Different from traditional hard cue engineering, P-tuning pioneers the introduction of learnable virtual markers. The newly upgraded v2 version implants intelligent cueing nodes in each layer of Transformer, like installing "context-aware antennas" for the model. This deep cueing optimization technology allows the model to show amazing context grasping ability in complex tasks such as reading comprehension and sentiment analysis, and can accurately decipher metaphorical expressions even in the face of professional domains.
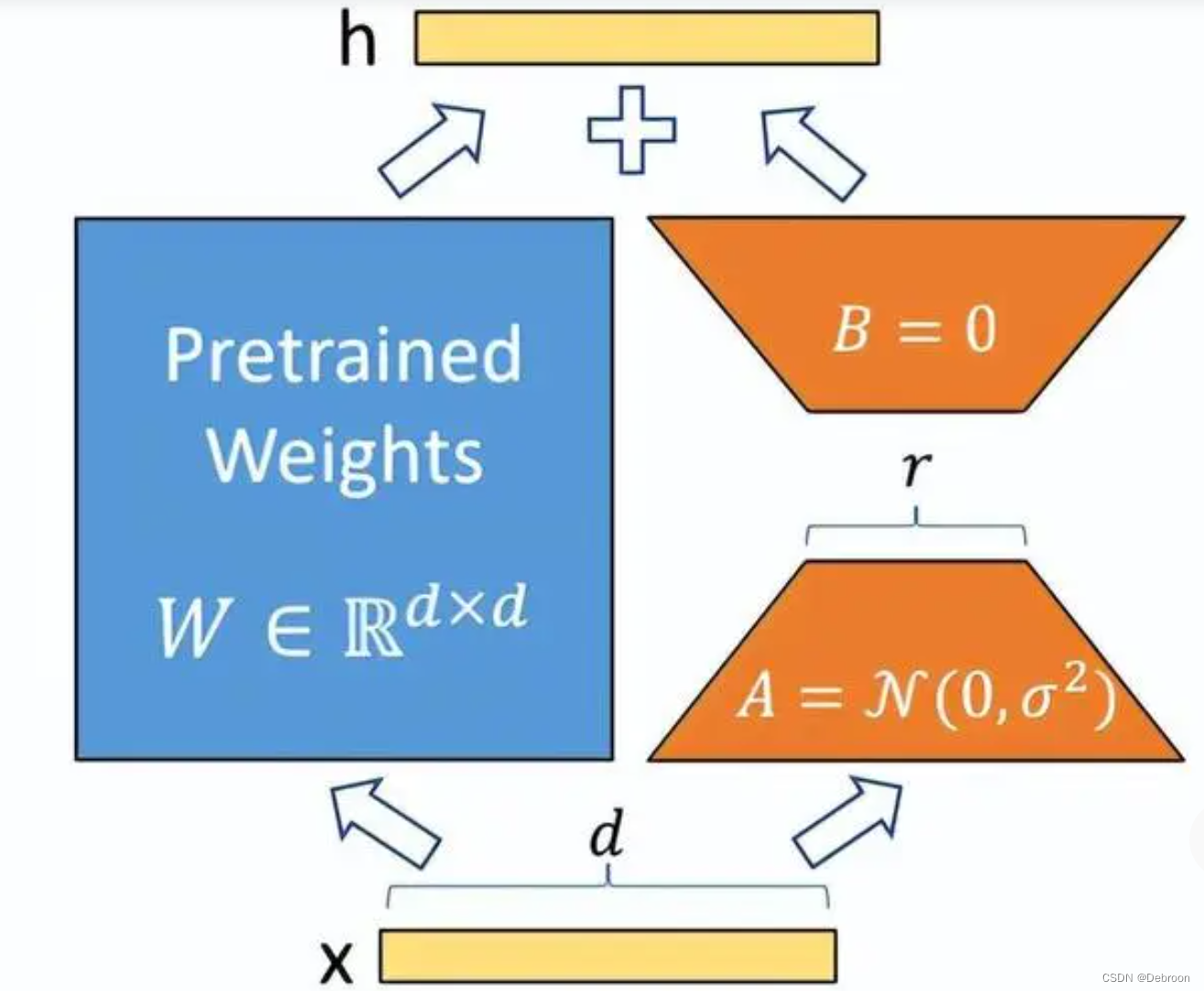
III. lora: the art of parameter-efficient fine-tuning
By means of "parameter surgery" realized by low-rank matrix decomposition, the Lora technique requires only one millionth of a trainable parameter to be adjusted under the premise of keeping 97% of the parameters of the original model frozen. This "four two dial a thousand pounds" fine-tuning way, so that a single GPU can manage hundreds of billions of parameter model domain adaptation. From intelligent customer service to code generation, Lora is becoming the standard for multi-tasking scenarios, and its modular design supports "plug-and-play" for different tasks.IV.
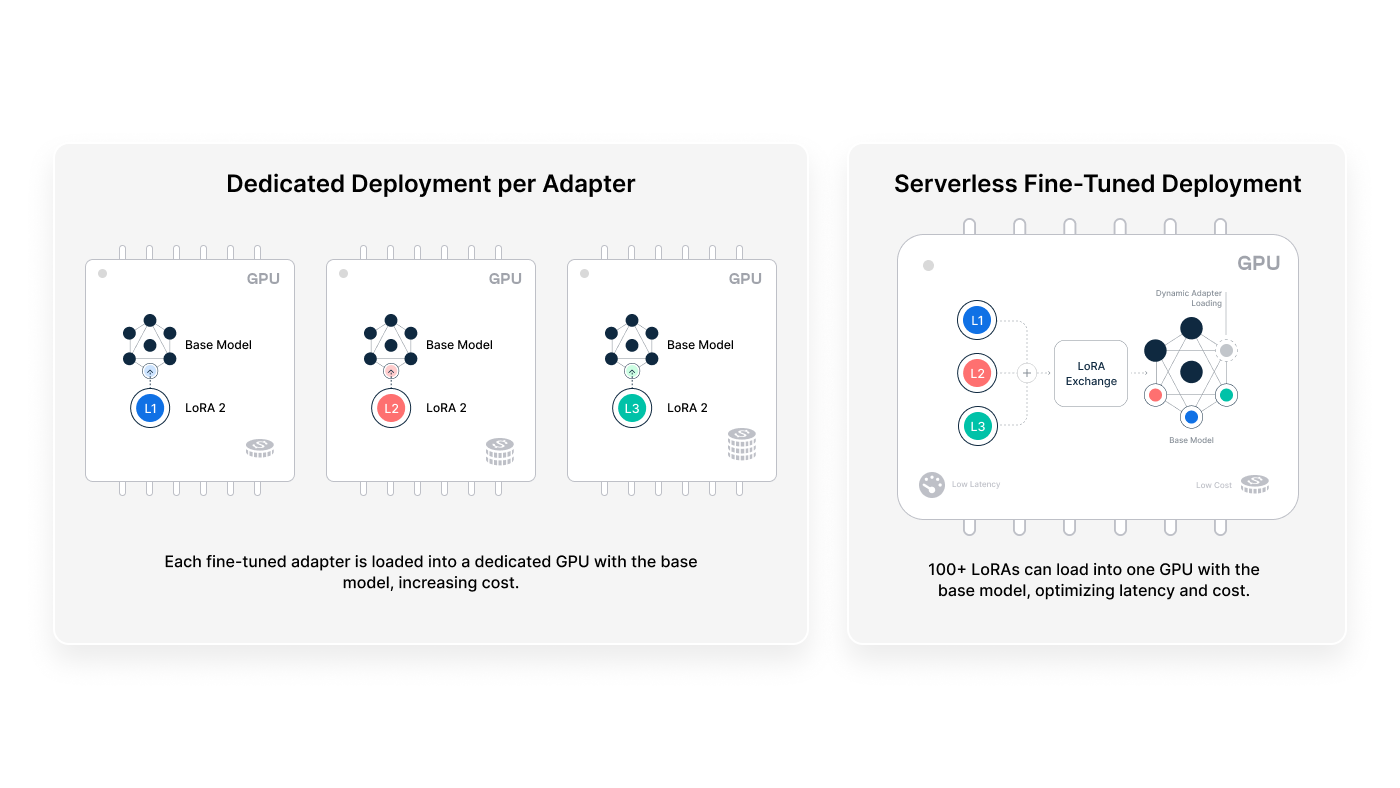
An ultra-lightweight adaptation based on 4-bit quantization, Qlora compresses the model memory footprint to 1/4 that of traditional methods. this "dancing with shackles" art of optimization allows researchers to fine-tune giant language models on consumer-grade graphics cards as well. When financial risk control systems need to update their fraud feature libraries in real-time, and when news aggregation platforms need to instantly adapt to hot topics, the deployment flexibility demonstrated by Qlora is redefining the boundaries of what is possible when AI hits the ground.
V. Distillation technology: the wisdom of small to large inheritance
Through the "teacher-take-an-apprentice" type of knowledge migration, distillation technology will be tens of billions of parameter models of wisdom condensed into one-tenth the size of the student model. This technological breakthrough not only makes it a reality for edge devices to run large models, but also creates a unique "model synergy effect" – the teacher’s model continues to evolve, and the student’s model is synchronized in real time. The real-time translation engine running on the smartphone side and the intelligent diagnostic system deployed in IoT devices are all witnessing the revolutionary power of this technology.
VI. Hint engineering: smart navigation without moving parameters
Reconstructing the "soft remodeling" of problem representation at the input level, Hint Engineering allows models to autonomously explore the solution space through well-designed sample guidance. From single-sample hints to less sample guidance, this "teaching to fish" tuning approach is rewriting the traditional perception of AI training. When medical AI needs to quickly adapt to newly discovered pathological features, and when educational robots need to instantly understand new pedagogies, zero-parameter-modification hint engineering shows amazing scene adaptability.
Practice guide: choosing your fine-tuning recipe

- Calculus-limited choose Freeze: fast verification of domain adaptation feasibility
- P-tuning for complex contexts: cracking the linguistic code in specialized domains
- Multitasking with Lora: Building a Modular AI Competency Matrix Mobile Deployment with Qlora: Finding Breakthroughs in Resource Constraints
- Try distillation with hardware constraints: the art of balancing performance and efficiency Instant Response by Hints: Agile Optimization for Immobile Models
Conclusion: Humanistic Thinking in the Evolution of Technology
As fine-tuning techniques continue to lower the threshold of AI customization, we are witnessing an epochal shift from "model hegemony" to "civilian AI". Each method is a skillful balance between the wisdom of engineers and the reality of arithmetic, all interpreting the technical philosophy of "suitable is optimal". At the dawn of this big model reshaping the industrial landscape, choosing the right fine-tuning strategy is to press the accelerator button for the intelligent future.